Detect label issues in your vision dataset.
Labeling data is an expensive process, both in terms of time and money. Troubleshooting why a model isn’t improving can be complex, and sometimes multiple things are at play. One possible issue we’ll discuss is that the labels you’re feeding to the model and validating against may be incorrect. You might be sending mixed signals to the model.
Of course, you could always manually inspect your data, and this may work for small datasets, but as data grows, it quickly becomes impractical. There are many ways to try and identify noise in the labels and we’ll explore one today.
K-fold cross-validation
Let’s break this down:
Cross-validationis a technique to evaluate the performance of a model by partitioning the original dataset. The model is trained on a subset of the data and validated on the remaining data.K-foldjust refers to the number (K) of partitions (folds) you create.
Here’s what K=5 folds look like:
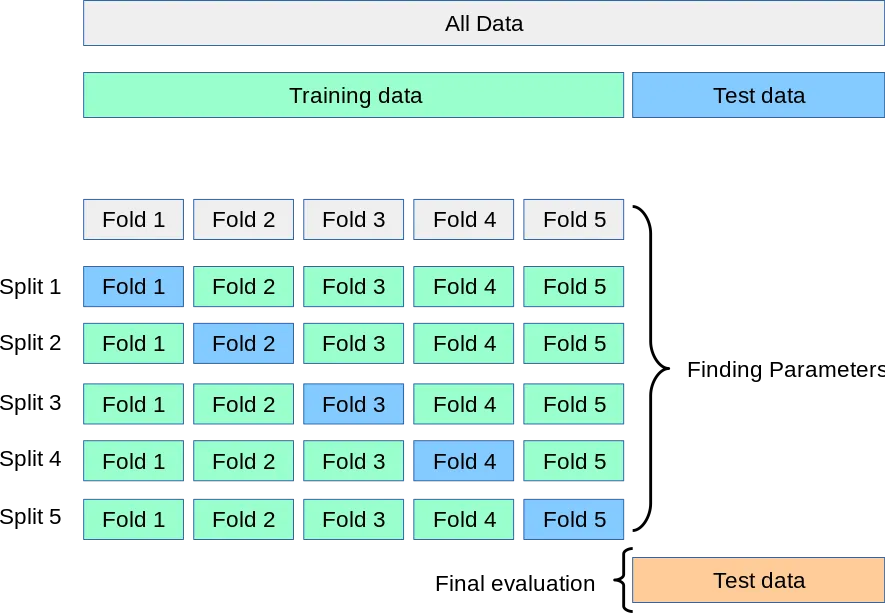
Image taken from scikit-learn
The dataset is split into K parts. For each fold, a model is trained on K-1 parts and validated on the remaining part. This process is repeated K times. This produces K models.
Dataset coverage
Traditionally, your dataset is split into a training and validation portion (e.g 80/20%). This is often chosen randomly. Excluding the test set, your model is only evaluated on a random slice of the data and you might miss potential issues that are present in the training data. Additionally, for small datasets using a single validation set can lead to high variance and the model might be good just because of pure luck of the randomness in the split.
K-fold cross-validation (CV) helps mitigate this by ensuring that every single data point becomes part of the validation set once. From the diagram above, you notice that a fold is held out for validation and the rest is used for training. We can cover the entire dataset and gain confidence that the model is performing well across the board.
Now, you might ask how does this help me identify label issues?.
While K-fold CV is often used for strict evaluation, we can repurpose it to identify potential issues in our dataset.
Detecting label issues
The goal is to spot potential issues in your dataset. For each fold, a model is trained on a slice of the data and evaluated on the remaining. The intuition here is that if a model struggles to predict a certain sample, it might be an indication that the label is incorrect or ambiguous. With traditional train/validation splits, you wouldn’t know how the model would perform on the training data because you can’t evaluate using it.
K=5 would produce 5 folds and thus 5 different models. After they’re all trained, we’ll want to generate Out of fold predictions for each model. This means that for each fold, we run inference on the held-out validation set, ensuring that every sample is only ever predicted by a model that never saw it during training. We’ll then gather all predictions and analyze them.
Let’s put this in practice:
- We’ll define an arbitrary
trainfunction. It’s not important how it’s implemented, just that it returns a trained model. - It’s important to train all
Kmodels with the same hyperparameters to ensure consistency. - We’ll use
sklearnto help us with the K-fold splitting. - We’ll assume some
DataFramefor our dataset. - We’ll only deal with three classes:
cat,dogandfish.
from sklearn.model_selection import KFoldimport pandas as pdfrom torch import Tensor, softmaxfrom random import random
dataset = pd.DataFrame( [ {"img": "img1.png", "label": "cat"}, {"img": "img2.png", "label": "dog"}, {"img": "img3.png", "label": "dog"}, {"img": "img4.png", "label": "dog"}, {"img": "img5.png", "label": "cat"}, {"img": "img6.png", "label": "fish"}, # ... ])
# Convert labels to numerical valuesdataset["label"] = dataset["label"].astype("category").cat.codes
folds = 3train_hyperparams = {}
# The actual implementation is not important heredef train(X, y, **kwargs): class Model: def predict(self, X) -> Tensor: # A logit per class logits = Tensor([[random(), random(), random()] for _ in X])
# Turn logits into probabilities return softmax(logits, dim=1) # Shape [len(X), 3]
return Model()
kf = KFold(n_splits=folds, shuffle=True, random_state=42)models = []
X = dataset["img"]y = dataset["label"]for train_idx, valid_idx in kf.split(X, y): X_train, X_valid = X[train_idx], X[valid_idx] y_train, y_valid = y[train_idx], y[valid_idx]
model = train(X_train, y_train, **train_hyperparams) models.append((model, X_valid, y_valid))Note: if your dataset is imbalanced, StratifiedKFold is often preferred over KFold because it preserves class proportions in each fold.
Note: K is a hyperparameter and you might want to experiment with different values. A common choice is K=5 or K=10. For very large datasets, you might even go as low as K=3 to reduce training time.
- Lower
Kmeans less models to train, less training data and bigger validation set - Higher
Kmeans more models to train, more training data and smaller validation set
Out of fold predictions (OOF)
Everything is trained, now it’s time to generate predictions on each model’s held out fold and gather them.
for fold, (model, X_valid, y_valid) in enumerate(models): targs = Tensor(y_valid.values) preds = model.predict(X_valid) # shape [len(X_valid), 3]There are a few signals we can look at for suspicious samples but to understand them, we’ll compute a few more values when running inference.
for fold, (model, X_valid, y_valid) in enumerate(models): targs = Tensor(y_valid.values) preds = model.predict(X_valid) # Get the best and second best prediction top2_vals, top2_idx = preds.topk(2, dim=1)
# Get the predicted class, equivalent to argmax. pred_idx = top2_idx[:, 0] confidence = top2_vals[:, 0]
# Compute the gap between the two highest probabilities # If the gap is big, the model is very confident in its prediction, otherwise it might be more of an ambiguous sample margin = top2_vals[:, 0] - top2_vals[:, 1]Finally, we’ll put everything in a DataFrame for analysis
rows = []
for fold, (model, X_valid, y_valid) in enumerate(models): targs = Tensor(y_valid.values) preds = model.predict(X_valid) # Get the best and second best prediction top2_vals, top2_idx = preds.topk(2, dim=1)
# Get the predicted class, equivalent to argmax. pred_idx = top2_idx[:, 0] confidence = top2_vals[:, 0]
# Compute the gap between the two highest probabilities # If the gap is big, the model is very confident in its prediction, otherwise it might be more of an ambiguous sample margin = top2_vals[:, 0] - top2_vals[:, 1]
for i in range(len(X_valid)): rows.append( { "fold": fold, "img": X_valid.iloc[i], "target": y_valid.iloc[i], "pred": int(pred_idx[i]), "confidence": float(confidence[i]), "margin": float(margin[i]), # p-true is the probability assigned to the true class. To not be confused with confidence which is the prob assigned to the predicted class. "p_true": float(preds[i][y_valid.iloc[i]]), } )
df = pd.DataFrame(rows)Our DataFrame will look something like this (your values will be different):
| fold | img | target | pred | confidence | margin | p_true |
|---|---|---|---|---|---|---|
| 0 | img1.png | 0 | 1 | 0.390691 | 0.040393 | 0.259010 |
| 0 | img2.png | 1 | 1 | 0.434935 | 0.119677 | 0.434935 |
| 1 | img3.png | 1 | 1 | 0.395865 | 0.091351 | 0.395865 |
| 1 | img5.png | 2 | 1 | 0.423618 | 0.059267 | 0.364351 |
| 2 | img4.png | 1 | 2 | 0.437047 | 0.149690 | 0.287357 |
| 2 | img6.png | 0 | 0 | 0.441312 | 0.089474 | 0.441312 |
Analyzing results
We want to send batches of images to humans for additional review. We can compute some sort of “suspicious score” based on the signals we collected from the model’s inference. For this blog post, we’ll especially look for:
- Wrong prediction with high confidence: If a model predicts the wrong class with high confidence, it might indicate a mislabeled sample. Think about it, the model learned patterns from the remaining data and is quite sure about its prediction, yet it’s wrong. This is a strong signal that the label might be incorrect and should be reviewed.
- Wrong prediction with low margin. If the margin is low, it means we’re right on the decision boundary and whether the model pick
AorBis arbitrary. This could indicate that the label is wrong or that the sample is ambiguous and should be reviewed.
With that in mind, we’ll define these two rules and compute a score.
df["wrong_highconf"] = ( (df["target"] != df["pred"]) & (df["confidence"] > 0.9)).astype(int)
df["wrong_lowmargin"] = ( (df["target"] != df["pred"]) & (df["margin"] < 0.1)).astype(int)
# Arbitrary weights, pick whatever makes sense for your use casew_highconf = 0.5w_lowmargin = 0.3w_invptrue = 0.2
df["suspicious_score"] = ( w_highconf * df["wrong_highconf"] + w_lowmargin * df["wrong_lowmargin"] + # Inverting p-true because raw p-true means high number = looks correct but in our suspicious score, we want high numbers to be = to highly suspicious. w_invptrue * (1 - df["p_true"]))| fold | img | target | pred | confidence | margin | p_true | wrong_highconf | wrong_lowmargin | suspicious_score |
|---|---|---|---|---|---|---|---|---|---|
| 0 | img1.png | 0 | 1 | 0.390691 | 0.040393 | 0.259010 | 0 | 1 | 0.448198 |
| 0 | img2.png | 1 | 1 | 0.434935 | 0.119677 | 0.434935 | 0 | 0 | 0.113013 |
| 1 | img3.png | 1 | 1 | 0.395865 | 0.091351 | 0.395865 | 0 | 0 | 0.120827 |
| 1 | img5.png | 2 | 1 | 0.423618 | 0.059267 | 0.364351 | 0 | 1 | 0.427130 |
| 2 | img4.png | 1 | 2 | 0.437047 | 0.149690 | 0.287357 | 0 | 0 | 0.142529 |
| 2 | img6.png | 0 | 0 | 0.441312 | 0.089474 | 0.441312 | 0 | 0 | 0.111738 |
There you go. Now you can sort and/or filter on suspicious_score and send batches for humans to further review.
Hold my beer, I’m writing to my human reviewer about img1 as we speak. Something looks fishy.
Conclusion
In this post, we explored how K-fold cross-validation can be repurposed beyond evaluation to spot potential labeling issues. By collecting out-of-fold predictions, we surface samples where the model’s confidence and the given labels don’t align — a strong indicator of noise, ambiguity, or outright mistakes.
This approach isn’t a silver bullet: it adds computational cost and should be combined with domain knowledge, especially in vision tasks where labels can be inherently subjective. But as datasets grow, it provides a scalable way to flag suspicious samples for human review.
If you’re struggling with inconsistent model performance, it might be worth trying this out.